


Gemini 3.0 is the strongest multimodal model on the planet – Google’s most powerful agentic and “vibe coding” system yet. It doesn’t just understand images, text, audio, and video; it orchestrates them. It delivers richer visualisations, deeper interactivity, and a level of reasoning that finally feels like AI is thinking, not just predicting.
Google calls this the beginning of the Gemini 3 era, and it shows. It’s the shift from “assistive AI” to autonomous intelligence.
Will it possess the power to surpass all rivals, including the newest GPT-5.1 model, and redefine the boundaries of AI? Let’s dive into it with GIANTY !
TL;DR
Gemini 3.0 is Google’s most powerful multimodal and agentic AI, capable of reasoning across text, images, audio, and video — and performing tasks, not just generating responses.
With Gemini Agent and Google Antigravity, it introduces true autonomous workflows: organizing inboxes, executing tasks, coding, validating, and running end-to-end projects.
Benchmarks show state-of-the-art performance, surpassing many frontier models in long-horizon planning, multimodal reasoning, and tool use.
Bold takeaway: Gemini 3.0 may become the first widely adopted Agentic AI — giving Google a real shot at overtaking OpenAI if it sparks a breakout moment like Nano Banana.

Why is Gemini “3.0” So Significant?
Every dot-zero (.0) release marks a fundamental change in the underlying architecture. The shift from 1.0 to 2.0 was about improved performance and stronger multimodality. But the leap to Gemini 3.0 is predicted to be a breakthrough in: “Learn anything – Build anything – Plan anything”.
Watch this introduction video to understand how Gemini 3.0 bring your idea to life:
True Multimodality
Currently, AIs process text, images, and audio almost separately before synthesising the output.
- Gemini 3.0 is expected to simultaneously and seamlessly reason and understand these data types, much like the human brain.
- Rich multimodal understanding, state-of-the-art reasoning and a 1 million-token context window (only for Pro & Ultra users) for synthesising and analysing, Gemini 3.0 is ready for anything.
For example, you feed it a video or anything up to an hour long and prompt for Gemini 3.0. It won’t just recognise the objects; it will also understand the emotion in the character’s voice and the historical context of the event happening, all in a single processing step.
It can even analyze videos of your pickleball match, identify areas where you can improve and generate a training plan for overall form improvements.
Gemini 3.0 can help you analyze complex information like research papers or documents (PDF) and can generate code for an interactive guide.
Gemini 3.0 and Google Antigravity
Gemini 3.0 transforms AI from a passive assistant into an active agent capable of planning, executing, and completing work.
1. Gemini Agent: AI That Handles Real Tasks
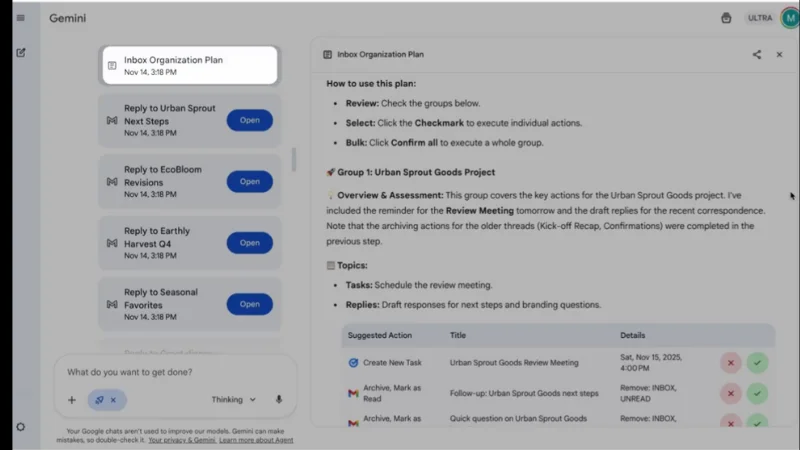
Gemini Agent can:
- Break complex tasks into smaller steps
- Connect to apps like Gmail and Calendar (with permission)
- Browse the web under your guidance
- Identify urgent emails and tasks
- Draft replies for you to review
- Organize your entire inbox via one command: “Organize my inbox.”
When using Gemini Agent, you can pause or take over at any time. And it will always ask for confirmation before taking critical actions like sending emails or making a purchase (for Google AI Ultra subscribers in the U.S. only. Just open the Gemini app, select “Agent” in the Tools drop-down).
2. A New Agent-First Development Era With Google Antigravity
Watch this amazing agent: Create a flight tracking app by iterating through UI designs generated with Nano Banana.
Google is launching Google Antigravity, a new agentic development platform built for Gemini 3.0’s advanced reasoning and tool-use capabilities.
Key features:
- Agents operate directly inside the editor, terminal, and browser
- Autonomous planning and execution of end-to-end software tasks
- Self-validated code generation
- Developers can work at a higher, task-oriented level
- Powered by a unified model stack:
- Gemini 3 Pro
- Gemini 2.5 Computer Use (browser control)
- Nano Banana (top-rated image editing model)
Can Gemini 3.0 beat Chat GPT5.1?
Gemini 3 Pro represents a step-change in reasoning – not an incremental upgrade, but a leap toward AI that thinks with depth, nuance, and genuine insight. It doesn’t just answer questions; it understands structure, identifies hidden relationships, and brings ideas to life through rich multimodal intelligence.
And the numbers prove it.
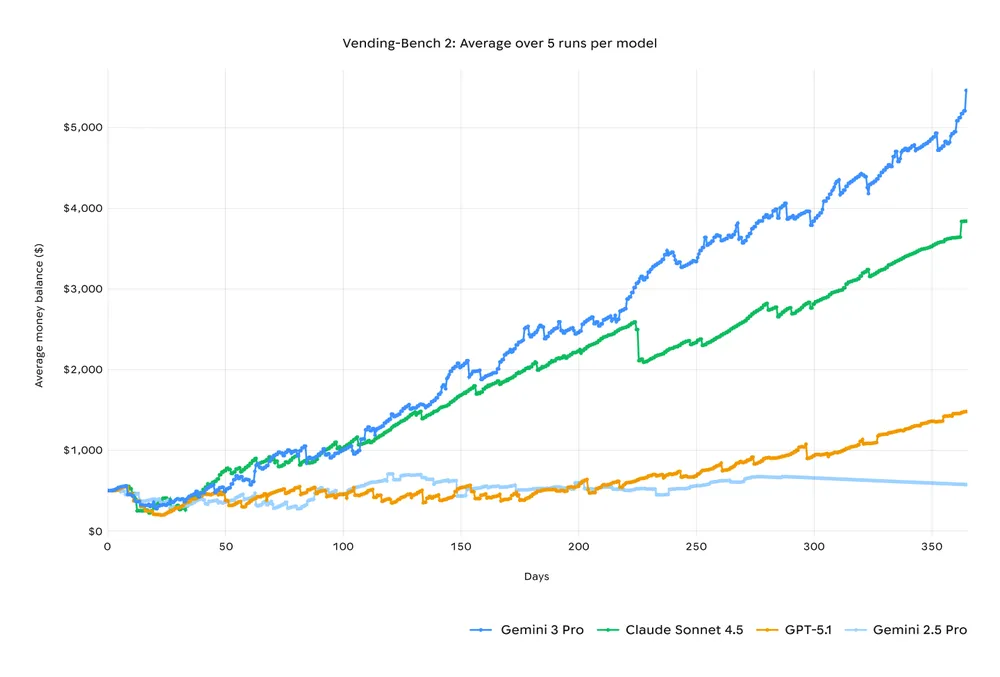
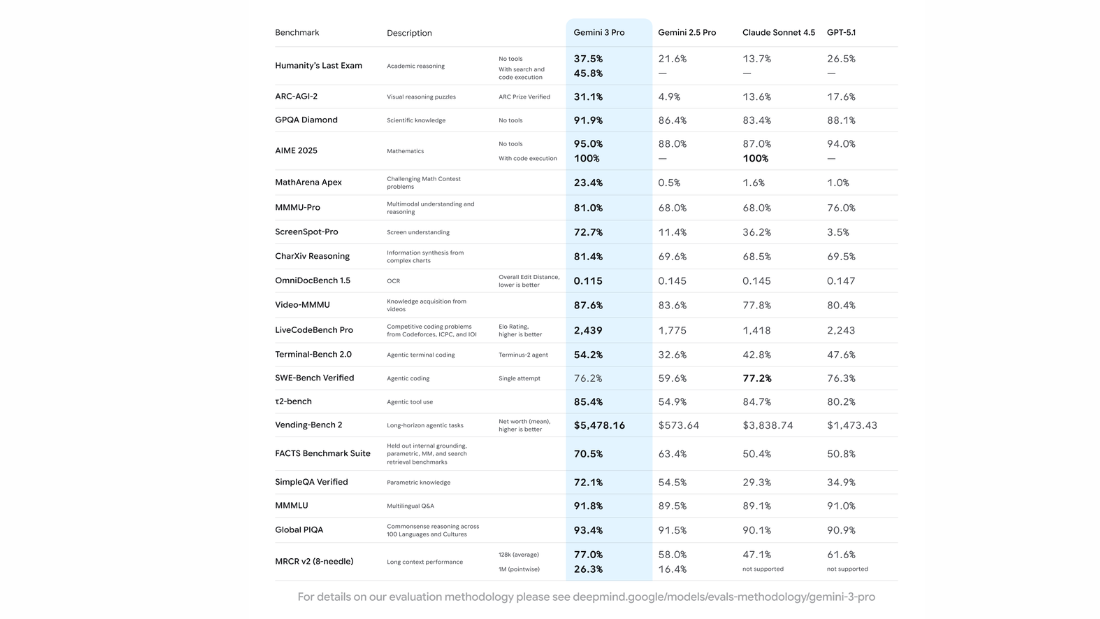
Bold Takeaway:
- Gemini 3.0 could become the first widely adopted “Agentic AI,” performing tasks instead of merely offering suggestions. This would make language-only focused models like GPT-5 feel less versatile in real-world environments.
- If Gemini 3.0 triggers a breakout moment like the kind of cultural surge we saw with Nano Banana, Google suddenly has a real opportunity to take back the lead in the AI race.
GIANTY’s pov: The Future is “Agentic AI”
This is the most critical takeaway. Gemini 3.0 marks the beginning of the Agentic AI era – a time when models don’t just answer questions, but autonomously execute tasks.
- In the old-school way: You ask, “What are the steps to set up a new website?”
- New agentic way: You instruct, “Set up a simple portfolio website for me.” The Agent will then plan the steps, write the code, find the images, and even integrate with a domain service, presenting you with a ready-to-launch product.
What does this mean for you as a user? The power of Gemini 3.0 Pro will be accessed differently:
- The casual user: Will type simple prompts and say, “It’s just slightly better.”
- The strategic user: Will learn to delegate, design workflows, and assign complex projects to the AI. This user will multiply their personal productivity and knowledge work output many times over.
Gemini 3.0 is a redefinition of what AI should be in this fast-paced. By shifting the focus from simple chatbots to autonomous, action-oriented agents, Google has potentially set the pace for the next generation of intelligence.
Maybe the new king of AI is here, but the battle for the crown has just begun. Stay updated with the newest AI news and analysis – subscribe to our newsletter and never miss a breakthrough.
FAQs
- What is multimodal AI?
Multimodal AI is an AI system that can understand and generate information across multiple formats: text, images, audio, video, and code and combine them for deeper, more accurate reasoning.
- What are the benefits of multimodal AI?
Multimodal AI delivers:
- More accurate understanding through cross-modal signals
- Stronger real-world reasoning
- Richer outputs like visualizations or code
- Higher reliability and factual consistency
- More natural, human-like interaction
- What makes Gemini 3.0 different from previous Gemini versions?
Gemini 3.0 introduces major upgrades in reasoning, planning, multimodal understanding, and agentic behavior. It doesn’t just answer questions but can perform tasks, use tools, operate apps, and execute multi-step workflows.
- What can Gemini 3 Pro do?
Gemini 3 Pro can:
- Organize emails and schedule tasks
- Draft and refine documents and responses
- Analyze images, videos, and scientific data
- Generate code and visualizations
- Plan multi-step workflows and execute tasks with agentic intelligence
- Is Gemini 3.0 better than GPT-5 for real-world use?
While GPT-5 excels at pure language generation, Gemini 3.0’s multimodal and agentic capabilities make it more versatile for real-world tasks from tool use to automation, planning, email management, coding, document analysis, and multimodal reasoning.








